

مقدمه مترجم
چند روز پیش، ایلان ماسک در گفتوگویی زنده اعلام کرد که منابع دادههای واقعی جهان برای آموزش مدلهای هوش مصنوعی به پایان رسیده است. او گفت:
«ما عملاً تمام دانش جمعی بشر را در آموزش هوش مصنوعی مصرف کردهایم».
این ادعا که توسط متخصصانی همچون ایلیا ساتسکِوِر نیز تأیید شده، پرسشی بنیادین را مطرح میکند: آیا پیشرفت هوش مصنوعی به بنبست رسیده است؟
مدلهای بزرگ هوش مصنوعی، مانند GPT-4، بر پایه حجم عظیمی از دادههای متنی و چندرسانهای آموزش دیدهاند. با این حال، تقریباً همه منابع ارزشمند دادهای جهان در این فرآیند مصرف شده و همین مسئله باعث شده است آینده توسعه این مدلها در هالهای از ابهام قرار گیرد. برخی بر این باورند که استفاده از دادههای مصنوعی – دادههایی که توسط خود مدلها تولید میشود – میتواند راهحلی برای این محدودیت باشد. اما این رویکرد نیز خطراتی همچون کاهش تنوع و دقت مدلها را به همراه دارد.
راهکار دیگری که اخیراً مورد توجه قرار گرفته است، گسترش توان استنتاج[۱] است. در این رویکرد، به جای تمرکز بر افزایش دادهها یا ساخت مدلهای عظیمتر، تلاش میشود تا با بهینهسازی محاسبات هنگام استفاده از مدل، عملکرد آن بهبود یابد. این تغییر رویکرد نشاندهنده تحولی اساسی در مسیر پیشرفت هوش مصنوعی است.
یادداشتی که در ادامه میخوانید، نوشته آرویند نارایانان و سایاش کاپور از دانشگاه پرینستون است. آنها با تحلیل روندهای اخیر هوش مصنوعی، این پرسش را مطرح کردهاند که آیا پیشرفت در این فناوری واقعاً متوقف شده یا صرفاً وارد مسیر تازهای شده است.
درباره نویسندگان و کتاب آنها
آرویند نارایانان، استاد علوم کامپیوتر و مدیر مرکز سیاست فناوری اطلاعات دانشگاه پرینستون و سایاش کاپور، دانشجوی دکترای علوم کامپیوتر در همین دانشگاه، از پژوهشگران پیشرو در حوزه تأثیرات اجتماعی و اخلاق هوش مصنوعی هستند.
آنها در کتاب خود با عنوان «روغنِ مارِ هوش مصنوعی؛ آنچه هوش مصنوعی میتواند انجام دهد، نمیتواند انجام دهد و چگونه این تفاوت را تشخیص دهیم[۲]» به بررسی علمی تواناییها و محدودیتهای هوش مصنوعی پرداختهاند. این کتاب که در سال ۲۰۲۴ منتشر شد، تلاش میکند مرز بین واقعیات و افسانههای پیرامون هوش مصنوعی را روشن کند. نویسندگان با نقد ادعاهای اغراقآمیز در مورد تواناییهای این فناوری، به خطرات ناشی از استفاده نادرست آن در حوزههایی مانند آموزش، پزشکی، بانکداری و عدالت اجتماعی اشاره کردهاند.
این یادداشت نیز بخشی از مجموعه AI Snake Oil است که با هدف تحلیل علمی و انتقادی تحولات اخیر هوش مصنوعی منتشر میشود.
این کتاب که در سال ۲۰۲۴ منتشر شد، تلاش میکند مرز بین واقعیات و افسانههای پیرامون هوش مصنوعی را روشن کند. نویسندگان با نقد ادعاهای اغراقآمیز در مورد تواناییهای این فناوری، به خطرات ناشی از استفاده نادرست آن در حوزههایی مانند آموزش، پزشکی، بانکداری و عدالت اجتماعی اشاره کردهاند.
آیا پیشرفت هوش مصنوعی در حال کند شدن است؟
پس از انتشار مدل GPT-4 در مارس ۲۰۲۳، روایت غالب در دنیای فناوری این بود که اگر ابعاد مدلهای هوش مصنوعی را مرتباً بزرگتر (مقیاسپذیری) کنیم، در نهایت به هوش مصنوعی عمومی[۳] و حتی ابرهوش[۴] خواهیم رسید. اما آن پیشبینیهای افراطی بهتدریج رنگ باخت. با این وجود تا حدود یک ماه پیش، باور غالب در صنعت هوش مصنوعی همچنان بر این بود که روند «مقیاسپذیری[۵]» مدلها برای مدتی ادامه خواهد یافت و مسیر پیشرفت به همان شکل قبلی پیش میرود.
سپس سه گزارش پیاپی در رسانههای The Information و Reuters و Bloomberg منتشر شد و نشان داد که سه شرکت پیشروی هوش مصنوعی — یعنی اوپنایآی[۶]، آنتروپیک[۷]، و گوگل (جمینای)[۸] — در توسعهی مدلهای نسل بعدی خود دچار مشکلات جدی شدهاند. در نتیجه، بسیاری از افراد مؤثر در این حوزه، از جمله ایلیا ساتسکِوِر[۹] (که یکی از مطرحترین طرفداران ایدۀ مقیاسپذیری مداوم مدلها بود) ناگهان تغییر موضع دادند:
«دهۀ ۲۰۱۰ دوران «مقیاسپذیری مدل» بود، اما حالا به عصر هیجان و اکتشاف برگشتهایم. همه بهدنبال چیز جدیدی هستند.» سوتسکِوِر میگوید: «مقیاسپذیری چیز درست حالا مهمتر از همیشه است.» (رویترز[۱۰])
بر اساس روایت تازه، دیگر دوران گسترش ابعاد مدلها به سر آمده و در عوض صحبت از «گسترش توان استنتاج» (Inference Scaling) یا همان «استفاده از توان محاسباتی بیشتر حین اجرای مدل» داغ شده است. در این رویکرد، هنگام استفاده از مدل ـ مثلاً برای پاسخ دادن به یک سؤال ـ سیستم بهطور مکرر «فکر میکند» و زمان محاسباتی بیشتری صرف میکند تا پاسخ بهتری بیابد.
در این میان، آنچه بسیاری از ناظران را سردرگم کرده، این است که آیا واقعاً روند رشد تواناییهای هوش مصنوعی کند شده یا نه. در این نوشتار، شواهد مربوط به این پرسش را بررسی کرده و به چهار نکتهی اساسی میپردازیم:
- هنوز زود است که مرگ مقیاسپذیری مدل را اعلام کنیم.
- چه گسترش مدل ادامه پیدا کند و چه نه، چرخش ناگهانی رهبران صنعت در این موضوع نشان میدهد که به پیشبینیهای آنان چندان هم نباید اعتماد کرد. آنها در بهترین حالت بهاندازهی دیگران از آینده آگاهاند و روایتهایشان بهشدت تحت تأثیر منافع سازمانی و شخصی خود است.
- گسترش توان استنتاج مفهومی واقعی است و احتمالاً در کوتاهمدت میتواند باعث جهشهای چشمگیر در برخی حوزهها شود. اما بعید است که این روند در همهی زمینهها روندی هموار و قابل پیشبینی داشته باشد.
- رابطهی پیشرفت در تواناییهای مدل با تأثیرات اقتصادی و اجتماعی آن بسیار ضعیف است. سرعت توسعهی محصول و نرخ پذیرش در جامعه محدودیتهای اصلی هستند، نه توانایی ذاتی مدلهای هوش مصنوعی.
آیا واقعاً دوران گسترش ابعاد مدلها به پایان رسیده است؟
واقعیت این است که هیچ اطلاعات جدید مهمی در هفتهها یا ماههای اخیر منتشر نشده که بخواهد این «تغییر جو» ناگهانی را توجیه کند. پیش از این نیز در خبرنامهمان گفته بودیم موانع قابل توجهی بر سر راه گسترش بیپایان مدلها وجود دارد و همان زمان هم هشدار داده بودیم که نباید بیشازحد دربارهی مقیاسپذیری خوشبین بود. حالا نیز باید بگوییم نباید در دام بدبینی افراطی افتاد.
با ظهور مدلهای کلاس GPT-4، مشخص شد که این مدلها عملاً از تمام دادههای متنی شناختهشده بهره گرفتهاند. از همان ابتدا میدانستیم برای ادامهی روند گسترش مدل، قطعاً ایدههای تازهای لازم است. بنابراین تا زمانی که شواهدی نبینیم مبنی بر اینکه ایدههای گوناگون امتحان و همه شکست خوردهاند، درست نیست نتیجه بگیریم که دیگر هیچ امیدی به پیشبرد «گسترش ابعاد مدل» وجود ندارد.
برای نمونه، یکی از ایدههای ممکن این است که اگر مدلهای چندرسانهای[۱۱] بتوانند ویدیوهای یوتیوب — ویدیوهای واقعی، نه صرفاً متن پیادهسازیشده از آنها — را در دادههای آموزشی خود بگنجانند، شاید تواناییهای جدیدی آزاد شود. ممکن هم هست چنین کاری کمکی نکند، اما تا زمانی که کسی آن را امتحان نکرده، نمیتوانیم پیشداوری کنیم. بهعلاوه، احتمالاً فقط گوگل میتواند چنین آزمایشی انجام دهد، چون غیرممکن بهنظر میرسد به رقبایش مجوز دسترسی گسترده به دادههای یوتیوب را بدهد.[۱۲]
بنابراین تا زمانی که شواهدی نبینیم مبنی بر اینکه ایدههای گوناگون امتحان و همه شکست خوردهاند، درست نیست نتیجه بگیریم که دیگر هیچ امیدی به پیشبرد «گسترش ابعاد مدل» وجود ندارد.
اما اگر تردیدها همچنان اینقدر زیاد است، پس چرا روایت غالب بهیکباره عوض شد؟ دلیل اول این است که حدود دو سال از پایان آموزش GPT-4 میگذرد و دیگر سخت میشود گفت «مدلهای نسل بعدی فقط کمی بیشتر زمان میخواهند.» دلیل دوم هم اینکه وقتی یک شرکت بپذیرد مشکلی دارد، شرکتهای دیگر هم راحتتر میتوانند این واقعیت را اعلام کنند و «سد انکار» را بشکنند. دلیل سوم، ورود مدل «استدلالی» «o1» از سوی اوپنایآی است: حالا شرکتها میتوانند بهجای اینکه بگویند «در گسترش مدل به بنبست خوردهایم»، بگویند «میخواهیم تمرکز را بگذاریم روی گسترش توان استنتاج.» و این ماجرا برایشان وجههی بهتری دارد.
البته تردیدی نیست که چند آزمایش بزرگتر از GPT-4 انجام شده، اما مدلهای حاصل از آنها به دلایلی منتشر نشدهاند. پرسش اینجاست که از این اتفاق دقیقاً چه باید نتیجه بگیریم. شاید دلایل زیر در عدم انتشارشان تأثیر داشته باشد:
- مشکل فنی، مانند بههمریختگی همگرایی[۱۳] یا عدم تابآوری[۱۴] در فرایند آموزش چند-دیتاسنتری.
- کیفیت مدل نهایی چندان بالاتر از GPT-4 نبود و شرکتها نمیخواستند مدل تازهای را که عملاً پیشرفت خاصی ندارد، رونمایی کنند.
- مدل نسبت به GPT-4 بهتر نبود و شرکتها در این فاصله در تلاش برای دستیابی به بهبود جزئی از طریق Fine-Tuning بودهاند.
در مجموع، احتمالاً این حقیقت دارد که این روند به نقطۀ اشباع رسیده و دیگر نمیشود با همان روشهای قدیمی به پیشرفت رسید. از طرف دیگر، ممکن است مشکلات کنونی موقتی باشد و در نهایت یکی از شرکتها بتواند موانع را برطرف و دادههای جدیدی را نیز پیدا کند و بار دیگر روند گسترش ابعاد را ادامه دهد.
بیایید اعتماد بیدلیل به «خودیهای» صنعت را کنار بگذاریم
نه تنها عجیب است که روایت جدید اینقدر سریع شکل گرفت، بلکه جالب است که روایت قدیمی با وجود محدودیتهای آشکار افزایش ابعاد مدلها، اینقدر طولانی پابرجا ماند. دلیل اصلی این پایداری، اطمینانهایی است که رهبران صنعت میدادند: اینکه افزایش ابعاد مدلها برای چند سال دیگر ادامه خواهد داشت.[۱۵] بهطور کلی، روزنامهنگاران (و اکثر دیگران) تمایل دارند به نظرات افراد درون صنعت بهعنوان مرجع، بیش از دیدگاههای افراد بیرونی تکیه کنند. اما آیا این اعتماد موجه است؟
رهبران صنعت در پیشبینی تحولات هوش مصنوعی سابقهی خوبی ندارند؛ نمونهی بارزی از این موضوع خوشبینی بیش از حد نسبت به خودروهای خودران در بیشتر دههی گذشته است. (خودرو خودران بالاخره به واقعیت پیوسته است، اگرچه سطح ۵ – خودکارسازی کامل – همچنان در دسترس نیست.) بعنوان نکتهای اضافه، برای درک بهتر عملکرد پیشبینیهای افراد درون صنعت، جالب خواهد بود که یک تحلیل سیستماتیک از کلیه پیشبینیهای مرتبط با هوش مصنوعی که در ده سال گذشته توسط افراد برجسته در این حوزه ارائه شده، انجام شود.
دلایلی وجود دارد که ممکن است بخواهیم به ادعاهای افراد درون صنعت اهمیت بیشتری بدهیم، اما دلایل مهمی نیز هست که باید وزن آنها کمتر شود. بیایید به تفکیک بررسی کنیم: درست است که افراد درون صنعت دارای اطلاعات درونی[۱۶] (مثلاً عملکرد مدلهایی که هنوز منتشر نشدهاند) هستند و این میتواند دقت پیشبینیهای آنان را درباره آینده افزایش دهد. اما با توجه به اینکه تعداد زیادی از شرکتهای هوش مصنوعی به لبه فناوری نزدیک هستند — از جمله شرکتهایی که وزنهای مدلهایشان را آزادانه منتشر میکنند و بینشهای علمی، مجموعهدادهها و دیگر منابع را به اشتراک میگذارند — این برتری اطلاعاتی در بهترین حالت تنها چند ماه جلوتر بودن محسوب میشود؛ که در قالب پیشبینیهایی با افق چندساله چندان اهمیتی ندارد.
افزون بر این، ما اغلب بر این باوریم که گویا شرکتهای بزرگ به انبوهی از اطلاعات ویژه دربارهی توانایی یا حتی ایمنی مدلهایشان دسترسی دارند که بقیه ندارند؛ افراد داخل صنعت مدتها هشدار میدادند: «کاش شما هم آنچه ما میدانیم را میدانستید…»؛ در حالی که افشاگریهای کارکنانشان نشان داده[۱۷] که بسیاری از آنها نیز بر اساس همان حدسها و شنیدهها صحبت میکردند که همۀ افراد بیرونی میزنند.
برخی ممکن است «تخصص فنی» مدیران یا پژوهشگران ارشد را دلیل اعتماد بدانند. اما فراموش نکنیم که در محیطهای آکادمیک نیز همان سطح از تخصص یافت میشود. مهمتر از همه اینکه برای پیشبینی روندهای کلی هوش مصنوعی، مثلاً در سه سال آینده، نیازی به سطح عمیق تخصص فنی در جزئیات پیچیدۀ مدلها نیست. از سوی دیگر، رشد فناوری تنها به عوامل فنی بستگی ندارد و جنبههای اقتصادی و اجتماعی هم نقش دارند. نمونهاش همان بحث خودروهای خودران است که میزان پذیرش عمومی برای آزمایش در جادهها، نقش بزرگی در سرنوشتشان داشت. در مورد مدلهای عظیم زبانی هم این سؤال اقتصادی مطرح است که «آیا مقیاسپذیری بیپایان برای شرکتها از نظر تجاری بهصرفه هست یا نه؟» پس نهتنها متخصصان فنی برتری مطلقی در پیشبینی ندارند، بلکه گاه این تمرکز بیشازحد بر بعد فنی باعث اعتمادبهنفس کاذب در پیشبینیها میشود.
در مقابل، یک دلیل کاملاً روشن وجود دارد که چرا نباید به آنها زیاد اعتماد کنیم: این افراد و شرکتها برای تحقق منافع تجاری خود، انگیزه دارند روایتهایی را جا بیندازند که بهسودشان باشد و بارها هم چنین کاری کردهاند. بهعنوان مثال، وقتی ایلیا سوتسکِوِر در اوپنایآی بود و شرکت برای جذب سرمایه به هیاهوی «مقیاسپذیری» نیاز داشت، از این ایده دفاع میکرد. حالا که در رأس استارتآپ «سِیف سوپراینتلیجنس[۱۸]» قرار دارد و بودجۀ محدودی در برابر غولهایی نظیر اوپنایآی، آنتروپیک و گوگل دارد، ناگهان سخن از تمام شدن دادههای باکیفیت و دوران تازهای میکند ـ گویی این موضوع تازه کشف شده است، درحالیکه بارها تکرار شده بود.
در نهایت، ما واقعاً نمیدانیم آیا روند مقیاسپذیری مدل به پایان رسیده یا نه. اما این چرخش ناگهانی و علنی نشان میدهد که «خودیهای[۱۹]» صنعت هم توپ را به زمین حدس و گمان میاندازند و دانش منحصربهفردی ندارند؛ علاوه بر آن، آنها خود در فضای بسته و متأثر از هیاهویی هستند که خودشان راه انداختهاند.
پیشنهاد ما، بهویژه به روزنامهنگاران، سیاستگذاران و جامعهی هوش مصنوعی، این است که از این به بعد اعتماد به پیشبینیهای رهبران این صنعت را ـ بهویژه دربارهی تأثیرات اجتماعی ـ بهشدت کاهش دهند. چنین کاری آسان نیست، چرا که ذهنیت عمومی در ایالات متحده اغلب ثروتِ افسانهای و قدرت را نشانهی «هوش و فضیلت» میگیرد و مدیران شرکتهای فناوری را فراتر از نقد میبیند. (اشاره به نقلقولی از برایان گاردینر[۲۰] در نقد کتاب Marietje Schake با عنوان «کودتای فناوری[۲۱]»)
یک دلیل کاملاً روشن وجود دارد که چرا نباید به آنها زیاد اعتماد کنیم: این افراد و شرکتها برای تحقق منافع تجاری خود، انگیزه دارند روایتهایی را جا بیندازند که بهسودشان باشد و بارها هم چنین کاری کردهاند. بهعنوان مثال، وقتی ایلیا سوتسکِوِر در اوپنایآی بود و شرکت برای جذب سرمایه به هیاهوی «مقیاسپذیری» نیاز داشت، از این ایده دفاع میکرد. حالا که در رأس استارتآپ «سِیف سوپراینتلیجنس» قرار دارد و بودجۀ محدودی در برابر غولهایی نظیر اوپنایآی، آنتروپیک و گوگل دارد، ناگهان سخن از تمام شدن دادههای باکیفیت و دوران تازهای میکند ـ گویی این موضوع تازه کشف شده است، درحالیکه بارها تکرار شده بود.
آیا پیشرفت در قابلیتها از طریق «گسترش توان استنتاج» ادامه خواهد یافت؟
بدیهی است مقیاسپذیری مدل تنها راه ارتقای تواناییهای هوش مصنوعی نیست. «گسترش توان استنتاج» روشی است که اخیراً پیشرفت زیادی داشته. برای نمونه، مدل «o1» از اوپنایآی و مدل متنباز مشابه با نام «دیپسیک آر وان[۲۲]»، هر دو مدلهایی هستند که آموزش دیدهاند «پیش از پاسخگویی» استدلال کنند. یا روشهایی وجود دارد که بدون تغییر در خود مدل، با تولید چند پاسخ مختلف و ارزیابی کیفیت آنها، عملکرد نهایی را بهتر میکند.
در این میان دو پرسش مهم وجود دارد که تعیین میکند تا چه حد میتوان به گسترش توان استنتاج امیدوار بود:
- این روش روی چه نوع مسائلی جواب میدهد؟
- وقتی رویکرد استنتاجی جواب میدهد، با صرف محاسبات بیشتر حین اجرا تا کجا میتوان پیش رفت؟
هزینۀ محاسباتی برای «هر توکن خروجی» در مدلهای زبانی[۲۳] بهسرعت رو به کاهش است — چه به دلیل پیشرفت در سختافزار و چه در الگوریتم — بنابراین اگر معلوم شود که با مصرف هزاران یا حتی میلیونها توکن در حین استنتاج میتوان بهبود چشمگیری بهدست آورد، تحولی بزرگ خواهد بود.[۲۴]
پاسخ ساده و شهودی به سؤال اول این است که گسترش توان استنتاج برای مسائلی مفید است که پاسخهای مشخص و درست دارند؛ مانند برنامهنویسی یا حل مسائل ریاضی که در آنها، حداقل یکی از دو نکته زیر صادق است: اول اینکه، مدلهای زبانی بهخاطر طبیعت آماریشان در استدلال نمادین[۲۵] ضعف دارند، اما میتوانند با ایجاد زنجیرههای استدلال در حین تولید پاسخ، دقت خود را بالا ببرند — انگار که انسان برای حل مسئله از قلم و کاغذ استفاده میکند. دوم اینکه، احراز و تأیید درستی راهحلها به مراتب آسانتر از یافتن آنها است (که گاهی با کمک ابزارهای خارجی مانند تستهای واحد در کدنویسی یا سیستمهای بررسی اثباتهای ریاضی انجام میشود).
اما در کارهایی مثل نویسندگی یا ترجمهی زبان، نمیتوان انتظار داشت «تفکر طولانیتر» مشکل کمبود داده یا دانش فرهنگی را جبران کند. مثلاً اگر در ترجمهی زبانی کممنبع[۲۶]، اگر مدل عبارات رایج و اصطلاحی آن زبان را نداند، با استدلال طولانیتر هم آنها را از جایی نخواهد آموخت.
در نمونههای فعلی نیز شواهد همین را تأیید میکند. در «o1»، پیشرفت محسوس عمدتاً در کارهایی مثل حل مسائل برنامهنویسی، ریاضی، امنیت سایبری، برنامهریزی در محیطهای آزمایشی[۲۷] و امتحانات مختلف نسبت به مدلهای زبانی پیشرفته مانند GPT-4o بهبودهایی نشان داده است. به نظر میرسد بهبودهای مشاهدهشده در امتحانات، بیشتر به اهمیت استدلال در پاسخ به سؤالها (نه صرفاً تکیه بر دانش یا خلاقیت) مربوط باشد؛ یعنی بهبودهای چشمگیر در ریاضیات، فیزیک و آزمونهای LSAT، پیشرفتهای کمتر در موضوعاتی مانند زیستشناسی و اقتصادسنجی، و تقریباً بدون تغییر در زبان انگلیسی. اما در کارهایی مانند نویسندگی، بخشهایی از امنیت سایبری که وابسته به «کنشگری» است، یا پرهیز از تولید متون نژادپرستانه و توهینآمیز، بهبود چشمگیری مشاهده نمیشود. همچنین شواهدی هم هست که در بعضی وظایف که «فکر کردن» انسان را گیجتر میکند، نتایج مدل هم بدتر میشود![۲۸]
در این زمینه ما یک صفحه اختصاصی راهاندازی کردهایم که شواهد موجود درباره مقایسه مدلهای استدلالی با مدلهای زبانی را گردآوری میکند و قصد داریم آن را فعلاً بهروز نگه داریم؛ گرچه انتظار داریم جریان رو بهرشد یافتههای جدید به زودی دنبال کردن آن را دشوار کند.
حال به سؤال دوم میپردازیم: با فرض اینکه بودجه محاسباتی نامحدودی برای استنتاج داشته باشیم، تا چه اندازه میتوانیم بهبود حاصل کنیم؟
نمونهی برجستهای که اوپنایآی برای نمایش تواناییهای «o1» ارائه داده، آزمون AIME (یک آزمون المپیادی در آمریکا) است؛ یک بنچمارک ریاضی. نمودار ارائهشده این سؤال را به طور جذابی باز میگذارد: آیا عملکرد مدل به نقطه اشباع نزدیک میشود یا میتوان آن را تا نزدیک ۱۰۰٪ بهبود داد؟ همچنین توجه کنید که نمودار بهطور عمده برچسبهای محور افقی (میزان توکنهای مصرفی) را حذف کرده است.
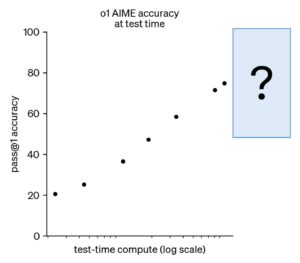
پژوهشگران مستقلی تلاش کردهاند آن را بازسازی کنند و دریافتهاند که احتمالاً در حدود دو هزار توکن متوقف میشود و اگر تعداد توکنها بیشتر شود، مدل دیگر واقعاً فرایند استدلال را طول نمیدهد. پس هنوز برای قضاوت قطعی زود است و باید منتظر آزمایشهایی با استفاده از مدلهای متنباز[۲۹] بمانیم تا تصویر واضحتری بدست آید. خوشبختانه، تلاشهای گستردهای برای بازتولید عمومی تکنیکهای در پس «o1» در جریان است.
در پژوهشی با عنوان «Inference Scaling fLaws» (بازی با کلمهی Laws و Flaws)، رویکرد دیگری برای گسترش توان استنتاج بررسی شده: در این حالت، بارها تلاش میکنیم جواب مسئله را تولید کنیم و از یک «ناظر بیرونی[۳۰]» برای تشخیص درستی پاسخ استفاده میکنیم. هر چند در ذهن خیلیها (از جمله خودمان در کارهای قدیمیتر) این ایده مطرح بود که میتوان با تکرار هزاران یا میلیونها بار تولید پاسخ و غربال پاسخهای اشتباه، دامنهی توانایی مدل را بسیار وسیع کرد، اما نتایج نشان میدهد اگر آن ناظر، کمی نقص داشته باشد، در بسیاری سناریوهای واقعی (مثلاً در کدنویسی) بعد از حدود ۱۰ بار تولید پاسخ، عملکرد به اوج میرسد و سپس کاهش مییابد.
بهطور کلی، شواهد موجود برای «قوانین گسترش توان استنتاج» چندان قانعکننده نیست و هنوز باید دید آیا در مسائل واقعی تولید (مثلاً) میلیونها توکن در زمان استنتاج واقعاً تأثیرگذار خواهد بود یا خیر.
آیا «گسترش توان استنتاج» همان افق اصلی آینده است؟
در کوتاهمدت، احتمالاً شاهد پیشرفتهای زیادی خواهیم بود، چون فعلاً فرصتهای آشکار زیادی برای بهبود در این روش وجود دارد. بهعنوان مثال، یکی از محدودیتهای فعلی مدلهای «استدلالی» آن است که در سیستمهای عامل-محور[۳۱] خوب عمل نمیکنند. در آزمونی به نام CORE-Bench (که از عوامل میخواهد کدهای ارائهشده در مقالات تحقیقاتی را بازتولید کنند) بهترین عامل با استفاده از «Claude 3.5 Sonnet» به ۳۸٪ امتیاز دست یافته، در حالی که «o1-mini» تنها ۲۴٪ کسب کرده است.[۳۲] همین، چرایی پیشرفت در برخی آزمونهای امنیت سایبری و عدم پیشرفت در برخی را توضیح میدهد — چون برخی آزمونها حول «عاملها» میچرخید.
ما فکر میکنیم دو دلیل وجود دارد که چرا عوامل از مدلهای استدلالی بهرهمند نمیشوند: اولین دلیل این است که این مدلها به شیوههای پرسش و پاسخ (prompting) خاصی نیاز دارند، در حالی که بیشتر سیستم عاملهای امروزی برای مدلهای زبانی معمولی بهینه شدهاند و نه برای مدلهای استدلالی. دوم اینکه، تا جایی که میدانیم، مدلهای استدلالی تاکنون با استفاده از یادگیری تقویتی در محیطی که بازخورد از محیط دریافت میکنند آموزش ندیدهاند؛ به عبارتی، آنها نمیتوانند کدی را اجرا کنند، به سیستمهای فرماندهی مانند شل (Shell) دسترسی داشته باشند یا در وب جستجو کنند. به همین علت توانایی استفاده از ابزارهایشان از مدل اولیهشان بهتر نشده است.[۳۳] به عبارت دیگر، توانایی استفاده از ابزارهای آنها هیچ بهتر از مدل اصلی قبل از یادگیری استدلال نیست.
این موارد را نسبتاً میشود با رویکردهای واضح برطرف کرد. اگر چنین شود، ممکن است سیستم عاملهای قدرتمندی پدید آید که مثلاً قادر باشند صرفاً با دریافت یک دستور، اپلیکیشنی پیچیده و کامل بنویسند. (ابزارهایی هستند که هدفشان همین است، اما حالا هنوز خروجیشان ضعیف است.)
اما در بلندمدت سؤال اصلی این است که آیا «گسترش توان استنتاج» میتواند همان نقشی را ایفا کند که مقیاسپذیری اندازهی مدل در هفت سال گذشته داشت؟ آن زمان، نقطهی هیجانانگیز این بود که صرفاً با بزرگتر کردن حجم دادهها، اندازهی مدل و نهایتاً توان محاسباتی، ناگهان جهشهای قابلتوجهی رخ میداد و نیاز زیادی به نوآوری الگوریتمی خاصی حس نمیشد.
این ویژگی در گسترش توان استنتاج وجود ندارد. ما با مجموعهای از تکنیکهای متفاوت سروکار داریم که هریک در حوزهی مشخصی کارآمد هستند و همگی در گسترهی محدودی از مسائل پاسخ میدهند. حال شرکتها میکوشند این محدودیت را رفع کنند. مثلاً، خدمت جدید «تنظیم دقیق تقویتی» (Reinforcement Finetuning) در اوپنایآی احتمالاً تلاشی است برای گردآوری داده از حوزههای مختلف از طریق مشتریانش تا آنها را روی مدل آینده به کار ببرد.
حدود یک دهه پیش، یادگیری تقویتی در بازیهایی مانند آتاری انقلابی برپا کرد و انتظار میرفت همین روش ما را به هوش مصنوعی عمومی (AGI) برساند؛ تا حدی که آزمایشگاههایی مثل اوپنایآی اصلاً با همین انگیزهی رسیدن به (AGI) از طریق یادگیری تقویتی (RL) شکل گرفتند. اما در عمل، اما آن تکنیکها فراتر از حوزههای محدودی مانند بازیها تعمیم نیافتند. حالا همان چرخهی هیجان دربارهی (RL) دوباره جریان دارد. بیشک روش بسیار توانمندی است، اما تاکنون محدودیتهای آشنای گذشته را در ابعاد وسیعتر هم نشان داده و مشخص نیست تا کجا میتواند توسعه یابد.
در نتیجه، پیشبینی سرعت پیشرفتهای آتی امکانپذیر نیست. حتی بر سر این که همین الان پیشرفت کند شده یا نه نیز اجماع نظر وجود ندارد، چون تفسیر شواهد بسته به این است که معیار «توانایی[۳۴]» چگونه تعریف شود.
آنچه با اطمینان بیشتری میتوان گفت این است که روند پیشرفت تواناییهای هوش مصنوعی در «گسترش توان استنتاج» نسبت به «گسترش ابعاد مدل» کاملاً متفاوت خواهد بود. در چند سال گذشته، مدلهای نوین سالانه در حوزههای متنوع پیشرفتهای قابلتوجهی داشتند؛ بهطوری که بسیاری از پژوهشگران خارج از آزمایشگاههای بزرگ اینگونه به نظر میرسیدند که جز نشستن و انتظار برای رونمایی از مدل زبان پیشرفته بعدی، کار بیشتری برای انجام وجود ندارد.
اما با «گسترش توان استنتاج»، بهبود تواناییها احتمالاً نامنظمتر و کمتر قابل پیشبینی خواهد بود؛ یعنی این پیشرفتها بیشتر ناشی از تغییرات الگوریتمی خواهند بود تا سرمایهگذاری در زیرساختهای سختافزاری. افزون بر این، بسیاری از ایدههایی که در دوران مدلهای زبان بزرگ کنار گذاشته شده بودند – مانند ایدههای موجود در ادبیات قدیمی برنامهریزی – دوباره وارد بحث شدهاند و به نظر میرسد فضای علمی امروزی پویاتر و زندهتر از چند سال گذشته شده است.
دود یک دهه پیش، یادگیری تقویتی در بازیهایی مانند آتاری انقلابی برپا کرد و انتظار میرفت همین روش ما را به هوش مصنوعی عمومی (AGI) برساند؛ تا حدی که آزمایشگاههایی مثل اوپنایآی اصلاً با همین انگیزهی رسیدن به (AGI) از طریق یادگیری تقویتی (RL) شکل گرفتند. اما در عمل، اما آن تکنیکها فراتر از حوزههای محدودی مانند بازیها تعمیم نیافتند.
فاصلۀ توسعۀ محصول از «قابلیت» مدلهای هوش مصنوعی
بحثهای شدید پیرامون اینکه آیا پیشرفت قابلیتها دچار کندی شده یا نه، نوعاً طنزآمیز است؛ چرا که در عمل ارتباط مستقیمی بین پیشرفتهای مدل و کاربرد واقعی آنها وجود ندارد. حتی قابلیتهای فعلی هوش مصنوعی نیز بهطور گسترده مورد استفاده قرار نگرفتهاند. یکی از دلایل این مسئله، فاصلهی زیادی است که بین «توانایی» یک مدل و «اعتمادپذیری» آن وجود دارد؛ یعنی گاهی یک مدل ممکن است در انجام کاری توانایی داشته باشد، اما بهطور مداوم و بدون خطا عمل نکند، بهطوری که نتوان آن را کاملاً جایگزین انسان کرد (مثلاً سامانۀ سفارش غذایی که تنها ۸۰ درصد مواقع درست کار کند، عملاً کاربردی نخواهد بود). روشهای افزایش اعتمادپذیری معمولاً مرتبط با پیادهسازی و کاربردهای خاص هستند و کمتر به بهبود خود معماری مدل میپردازند. از طرفی، مدلهای استدلالی نیز به نظر میرسد که در بهبود قابلیت اطمینان پیشرفتهایی داشتهاند که خبر خوبی محسوب میشود.
برای درک بهتر این موضوع، میتوان چند قیاس مطرح کرد که نشان میدهد چرا ساخت محصولاتی که حتی از قابلیتهای فعلی هوش مصنوعی بهطور کامل بهره ببرند، ممکن است یک دهه یا بیشتر طول بکشد. فناوری پشت اینترنت و وب عمدتاً در اواسط دههی ۹۰ تثبیت شد، اما تکمیل پتانسیل اپلیکیشنهای تحت وب حدود یکی دو دهه طول کشید. دوم، مقالهای تأملبرانگیز پیشنهاد میکند که برای مدلهای زبانی بزرگ باید واسطهای گرافیکی (GUI) ساخته شود تا بتوان با پهنای باند بسیار بیشتری نسبت به نوشتار با آنها ارتباط برقرار کرد. از این منظر، وضعیت فعلی محصولات هوش مصنوعی مانند روزهای اولیه کامپیوترهای شخصی قبل از ظهور GUI به نظر میرسد.
علاوه بر این، غولهای فناوری هوش مصنوعی مدتها روی توسعهی «محصول» تمرکز نداشتند و تصور میکردند طبیعت چندمنظورۀ هوش مصنوعی، آنها را از مشکلات سخت مهندسی نرمافزار معاف میکند و درنتیجه نیازی به تلاش در جهت توسعۀ نرمافزار و طراحی تجربۀ کاربری وجود ندارد. اما اخیراً این نگرش تغییر کرده و توجه بیشتری به جنبههای محصول و کاربردی شدن مدلها میشود.
حالا که روی محصول متمرکز شدهاند، هم خود شرکتها و هم کاربرانشان در حال کشف مجدد این واقعیت هستند که توسعۀ نرمافزار، بهخصوص در زمینۀ تجربۀ کاربری، کاری ظریف است و نیازمند مهارتهایی فراتر از صرف مدلسازی هوش مصنوعی است. مثالی جالب توجه این است که هماکنون دو روش مختلف برای اجرای کد پایتون در چتجیپیتی عرضه شده و هر کدام هم محدودیتها و قواعد ناشناختۀ خاص خود را دارند. «سایمون ویلیسون[۳۵]» میگوید:
«آیا همۀ اینها گیجکننده نیست؟ حق دارید چنین فکری کنید. من که بیش از ۲۰ سال برنامهنویس پایتون و توسعهدهندۀ وب هستم هم بهسختی میتوانم این همه محدودیت و جزئیات را به خاطر بسپارم.»
البته همین هم پیشرفتی است نسبت به یک هفتۀ پیش که مدلهای قدرتمند کدنویسی اصلاً امکان اجرای کدی که به اینترنت دسترسی داشته باشد را نداشتند! حتی، اکنون، مدل «o1» نه میتواند به اینترنت متصل شود و نه کدی را اجرا کند. پس از منظر تأثیر اجتماعی هوش مصنوعی، چیزی که مهمتر از پیشرفت ذاتی مدلهاست، ساخت محصولاتی است که اجازه دهد مردم از همین قابلیتهای کنونی بهترین استفاده را ببرند.
در نهایت، بُعد «پذیرش در جامعه» بسیار کندتر از بُعد «توسعۀ محصول» حرکت میکند. موانع مختلف انسانی، سازمانی و اجتماعی باعث میشود که حتی اگر محصول مناسب هم عرضه شود، تا تثبیت کاربرد آن در زندگی روزمره زمان زیادی لازم باشد. بنابراین افرادی که دغدغۀ آثار مثبت و منفی هوش مصنوعی را دارند، بهتر است بر فرایند شکلگیری محصولات و الگوهای پذیرش آنها متمرکز شوند تا اینکه صرفاً در انتظار «نسل بعدی مدل» بنشینند.
جمعبندی
شاید دوران رشد ابعاد مدلهای هوش مصنوعی به پایان رسیده باشد یا شاید ادامه داشته باشد؛ اما بدون شک این روند برای همیشه دوام نخواهد داشت. پایان این دوره نکات مثبتی به همراه دارد. از یک طرف، پیشرفت هوش مصنوعی دوباره نیازمند نوآوری و ایدههای تازه است و تنها تکیه بر توان محاسباتی کافی نخواهد بود. از طرف دیگر، شرکتهای بزرگ، استارتآپها و دانشگاهها میتوانند در یک زمینه رقابتی نسبتاً برابر شرکت کنند. همچنین، مقرراتی که قبلاً فقط بر میزان محاسبات در زمان آموزش تمرکز داشتند، دیگر قابل استدلال نخواهند بود؛ و بالاخره مشخص شده که مدلها به تنهایی «محصول» محسوب نمیشوند، بلکه یک فناوری هستند که باید به شکل محصولات کاربردی عرضه شوند.
اما در مورد آیندۀ هوش مصنوعی باید بدانیم که حتی متخصصان حوزه نیز مانند بقیه افراد در حال حدس زدن آیندهاند. بنابراین نباید بدون تردید به پیشبینیهای مطمئن اما مبهم آنها اعتماد کنیم؛ بهویژه زمانی که صحبت از تأثیرات اجتماعی میشود، چرا که در این زمینه حتی از جنبههای فنی هم اطلاعات کافی نداریم و علاقهمندیهای اقتصادی و سایر منافع پشت بسیاری از اظهارات وجود دارد.
سپاسگزاری
از «زکری سی. سیگل[۳۶]» بابت بازخوردهای ارزشمندش روی پیشنویس این متن سپاسگزاریم.






